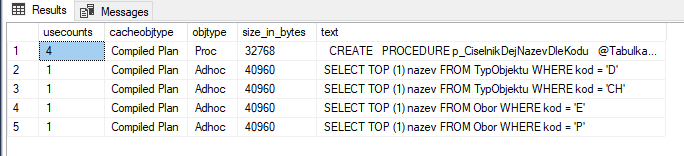
Kde najít info k proběhlému deadlocku? Od SQL 2012 v by default zapnuté extended event session system_health. Možná je to už od 2008, ale tam to má jiný formát a neznám nikoho, kdo by to tam chtěl hledat ![]() V sytem_health se loguje více věcí než deadlocky, má omezenou velikost a funguje tak, že nově logované události přepisují ty nejstarší. Na vytíženém serveru tam nemusí být historie ani za celý den.
V sytem_health se loguje více věcí než deadlocky, má omezenou velikost a funguje tak, že nově logované události přepisují ty nejstarší. Na vytíženém serveru tam nemusí být historie ani za celý den.
Lepší je si založit vlastní session jen na deadlocky. Třeba takto:
CREATE EVENT SESSION [deadlocks] ON SERVER ADD EVENT sqlserver.xml_deadlock_report ADD TARGET package0.event_file(SET filename=N'deadlocks.xel',max_file_size=(20),max_rollover_files=(4)) WITH (MAX_MEMORY=4096 KB,EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS,MAX_DISPATCH_LATENCY=120 SECONDS,MAX_EVENT_SIZE=0 KB,MEMORY_PARTITION_MODE=NONE,TRACK_CAUSALITY=OFF,STARTUP_STATE=ON) GO
A teď fotoseríál jak z Bravíčka, jak se k těm informacím doklikat.
V Object Exploreru je to Management/Extended Events/Sessions/system_health a poklikat event_file
Já pak dávám Grouping, abych ten zmatek trochu zpřehlednil
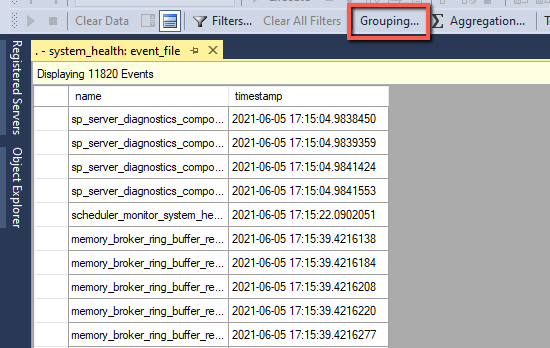
Podle názvu události
Pak už je k nalezení deadlock, pokud je nějaký zalogovaný. Z deadlock grafu je vidět akorát o kterou jde databázi a o které tabulky se tam soupeřilo.
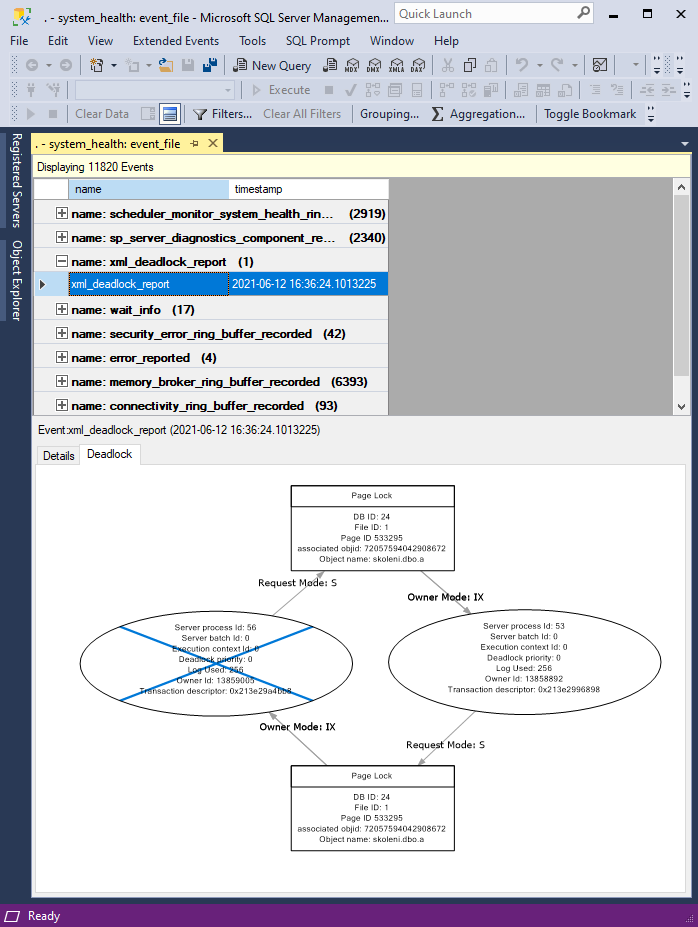
Všechny informace jsou pak v XML, které dostanem na panelu Details po poklikání na XML.
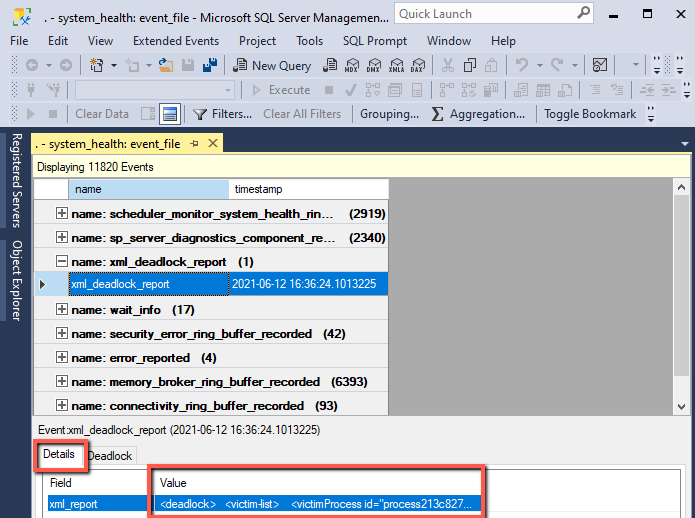
V XML jsou pak stacky volání a konkrétní dotazy, které se deadlocku zúčastnily a taky zdroje o které tam šlo. Zdroje tam jsou uvedené v podobě waitresource. Pokud je potřeba zjistit o který konkrétní záznam v tabulce šlo, tak tady Kendra Little popisuje jak ten waitresource rozkódovat.