Ve zděděném kódu občas potkávám UPDATE tabulka WITH (UPDLOCK) SET… a nikdo mi k tomu nechtěl říct jestli to je k něčemu dobré. Teorie praví, že pro vyhledání updatovaného záznamu se použije U zámek a updatovaný záznam pak dostane X zámek, který se drží do konce transakce. Hint WITH (UPDLOCK) by měl zaručit držení U zámku do konce transakce. Pojďme si to zkusit v praxi.
Zkoušet to budeme na 3 tabulkách. Za prvé na haldě bez primárního klíče. Za druhé na haldě s neklastrovaným primárním klíčem. A za třetí na tabulce s klastrovaným primáním klíčem, kterou ještě okořeníme druhým indexovaným klíčem.
CREATE TABLE dbo.halda(
id INT NOT NULL,
data VARCHAR(500) NULL
)
CREATE TABLE dbo.haldaPK(
id INT NOT NULL CONSTRAINT pk_haldaPK PRIMARY KEY NONCLUSTERED,
data VARCHAR(500) NULL
)
CREATE TABLE dbo.tabulka(
id INT NOT NULL CONSTRAINT pk_tabulka PRIMARY KEY CLUSTERED,
dalsiKlic VARCHAR(50) NOT NULL CONSTRAINT uq_tabulka_dalsiKlic UNIQUE,
data VARCHAR(50) NULL
)
GO
Naplníme nějakými testovacími daty
INSERT INTO dbo.halda(id, data)
VALUES(1,'a'),(2,'b'),(3,'c')
INSERT INTO dbo.haldaPK(id, data)
VALUES(1,'a'),(2,'b'),(3,'c')
INSERT INTO dbo.tabulka(id,dalsiKlic,data)
VALUES(1,'a','dataA'),(2,'b','dataB'),(3,'c','dataC')
GO
A jdeme zkoušet updaty. Nejdříve na haldě.
BEGIN TRAN
UPDATE dbo.halda WITH (UPDLOCK) SET data = 'x' WHERE id = 3
EXEC sp_lock @spid1 = @@SPID
ROLLBACK
/*
spid dbid ObjId IndId Type Resource Mode Status
------ ------ ----------- ------ ---- -------------------------------- -------- ------
61 32 0 0 DB S GRANT
61 32 1845581613 0 RID 1:40441:2 X GRANT
61 32 1845581613 0 PAG 1:40441 IX GRANT
61 32 1845581613 0 TAB IX GRANT
61 1 1467152272 0 TAB IS GRANT
61 32767 -571204656 0 TAB Sch-S GRANT
*/
Hmm, tak na první pokus žádný U zámek.
Zkusíme haldu s primárním klíčem.
BEGIN TRAN
UPDATE dbo.haldaPK WITH (UPDLOCK) SET data = 'x' WHERE id = 3
EXEC sp_lock @spid1 = @@SPID
ROLLBACK
/*
spid dbid ObjId IndId Type Resource Mode Status
------ ------ ----------- ------ ---- -------------------------------- -------- ------
61 32 0 0 DB S GRANT
61 32 1861581670 2 KEY (98ec012aa510) U GRANT
61 32 1861581670 0 RID 1:8089:2 X GRANT
61 32 1861581670 0 TAB IX GRANT
61 32 1861581670 0 PAG 1:8089 IX GRANT
61 32 1861581670 2 PAG 1:16177 IU GRANT
61 1 1467152272 0 TAB IS GRANT
61 32767 -571204656 0 TAB Sch-S GRANT
*/
Tady už se něco událo. Vidíme X zámek na záznamu na haldě a U zámek na záznamu indexu primárního klíče.
Teď zkusme update tabulky s klastrovaným primárním klíčem, kde budeme vyhledávat právě podle toho primárního klíče.
BEGIN TRAN
UPDATE dbo.tabulka WITH (UPDLOCK) SET data = 'x' WHERE id = 3
EXEC sp_lock @spid1 = @@SPID
ROLLBACK
/*
spid dbid ObjId IndId Type Resource Mode Status
------ ------ ----------- ------ ---- -------------------------------- -------- ------
61 32 0 0 DB S GRANT
61 32 1909581841 1 KEY (98ec012aa510) X GRANT
61 32 1909581841 0 TAB IX GRANT
61 32 1909581841 1 PAG 1:24265 IX GRANT
61 1 1467152272 0 TAB IS GRANT
61 32767 -571204656 0 TAB Sch-S GRANT
*/
A tentokrát zase žádný U zámek.
Naposledy zkusíme hledat v klastrované tabulce podle jiného klíče než primárního.
BEGIN TRAN
UPDATE dbo.tabulka WITH (UPDLOCK) SET data = 'x' WHERE dalsiKlic = 'c'
EXEC sp_lock @spid1 = @@SPID
ROLLBACK
/*
spid dbid ObjId IndId Type Resource Mode Status
------ ------ ----------- ------ ---- -------------------------------- -------- ------
61 32 0 0 DB S GRANT
61 32 1909581841 1 KEY (98ec012aa510) X GRANT
61 32 1909581841 0 TAB IX GRANT
61 32 1909581841 2 KEY (f037bcc414ff) U GRANT
61 32 1909581841 1 PAG 1:24265 IX GRANT
61 1 1467152272 0 TAB IS GRANT
61 32767 -571204656 0 TAB Sch-S GRANT
61 32 1909581841 2 PAG 1:32353 IU GRANT
*/
Zafungovalo to. Updatovaný záznam v klastrovaném indexu je zamčený X zámkem a záznam v unikátním indexu je zamčený U zámkem.
Závěr
Závěrem zatím budiž to, že při použití WITH (UPDLOCK) se U zámek drží do konce transakce na záznamu indexu, podle kterého se vyhledávalo, pokud je tento rozdílný od podkladové struktury, která drží data (halda, klastrovaný index).
Využití
Hodně jsem se snažil najít nějaký pěkný příklad, k čemu je to dobré. Ale našel jsem jen jeden dost pochybný. Pokud mám nějaký kód, který v jedné transakci dvakrát updatuje stejný řádek a navíc je tento kód vykonáván paralelně ve dvou vláknech nad stejným záznamem. V takovém případě může dojít k deadlocku, kterému se dá zabránit právě tím UPDATE WITH (UPDLOCK).
Příkladem budiž:
BEGIN TRAN
UPDATE dbo.tabulka SET data = 'x' WHERE dalsiKlic = 'c'
--nejaka dalsi prace
WAITFOR DELAY '0:0:10'
UPDATE dbo.tabulka SET data = 'x' WHERE dalsiKlic = 'c'
COMMIT
Tohle když spustím ve dvou oknech SSMS, tak mi to v jednom okně upadne na deadlock.
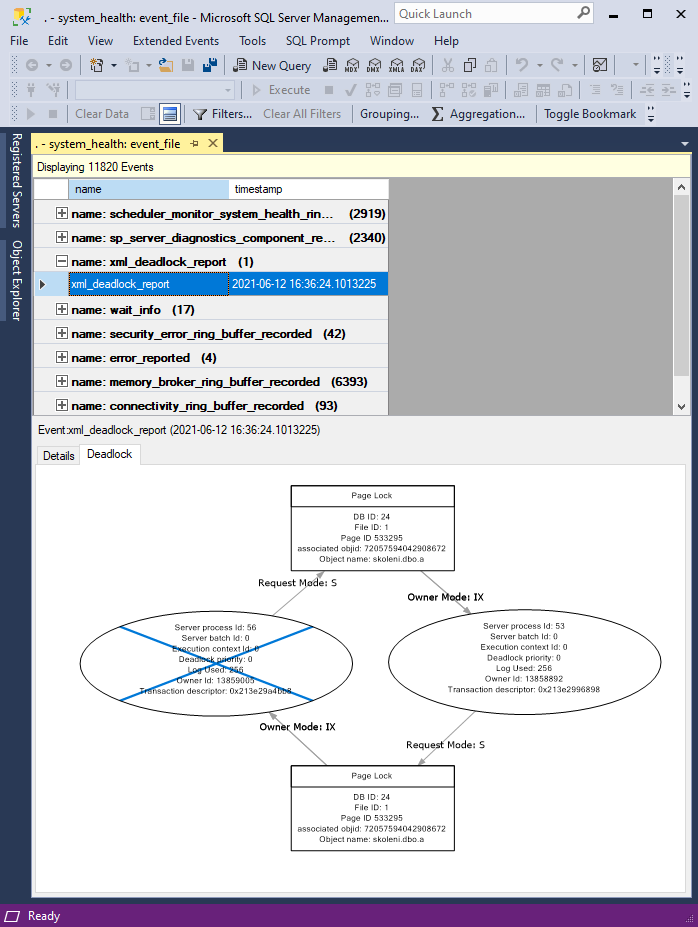
Mechanismus je takový, že se provede první update v prvním okně a na záznamu v klastrovaném indexu je pak držen X zámek. První update ve druhém okně pak provede jen vyhledání záznamu k updatu v unikátním indexu, který si označí U zámkem. Následně se pokusí označit U zámkem i záznam v klastrovaném indexu, což nebude kompatibilní s již uvaleným X zámkem, takže zůstane čekat na jeho uvolnění. Transakce v prvním okně mezitím dojde k druhému updatu. Pokusí se vyhledat záznam pro update v unikátním klíči a uvalit na něj U zámek, což nebude kompatibilní s již uvaleným U zámkem z druhé transakce. Dostaneme se tedy do situace, kdy první transakce čeká na druhou a druhá na první. Deadlock. SQL server jednu vybere a sestřelí.
Předejít tomu jde přidáním WITH (UPDLOCK) na první update.
BEGIN TRAN
UPDATE dbo.tabulka WITH (UPDLOCK) SET data = 'x' WHERE dalsiKlic = 'c'
--nejaka dalsi prace
WAITFOR DELAY '0:0:10'
UPDATE dbo.tabulka SET data = 'x' WHERE dalsiKlic = 'c'
COMMIT
V takovém případě zůstane po prvním updatu v prvním okně držen X zámek na záznamu v klastrovaném indexu a U zámek na záznamu v unikátním indexu. Transakci v druhém okně se už nepovede přidat U zámek na záznam v unikátním indexu a zůstane tedy čekat. Zároveň už nebude nijak omezovat transakci z prvního okna v úspěšném dokončení.